什么是MAGI-1 AI?
MAGI-1是由 SandAI开发的先进自回归视频生成模型,通过以自回归方式预测视频片段序列来生成高质量视频。该模型经过训练可以对视频片段进行降噪,实现因果时序建模并支持流式生成。 MAGI-1在图像到视频(I2V)任务中表现出色,得益于多项算法创新和专用基础设施栈,提供高时序一致性和可扩展性。
MAGI-1概述
| 特征 | 描述 |
|---|---|
| AI工具 | MAGI-1 |
| 类别 | 自回归视频生成模型 |
| 功能 | 视频生成 |
| 生成速度 | 高效视频生成 |
| 研究论文 | 研究论文 |
| 官方网站 | GitHub - SandAI-org/MAGI-1 |
MAGI-1 AI:模型特点
基于Transformer的VAE
使用基于Transformer架构的变分自编码器,提供8倍空间和4倍时间压缩。这带来了快速解码时间和具有竞争力的重建质量。
自回归降噪算法
逐块生成视频,允许同时处理最多四个块以实现高效的视频生成。每个块(24帧)都进行整体降噪,当前块达到特定降噪水平后立即开始下一个块的生成。

扩散模型架构
基于扩散Transformer构建,融入了Block-Causal Attention、Parallel Attention Block、QK-Norm和GQA等创新。在FFN中采用Sandwich Normalization、SwiGLU和Softcap Modulation,以提高大规模训练效率和稳定性。
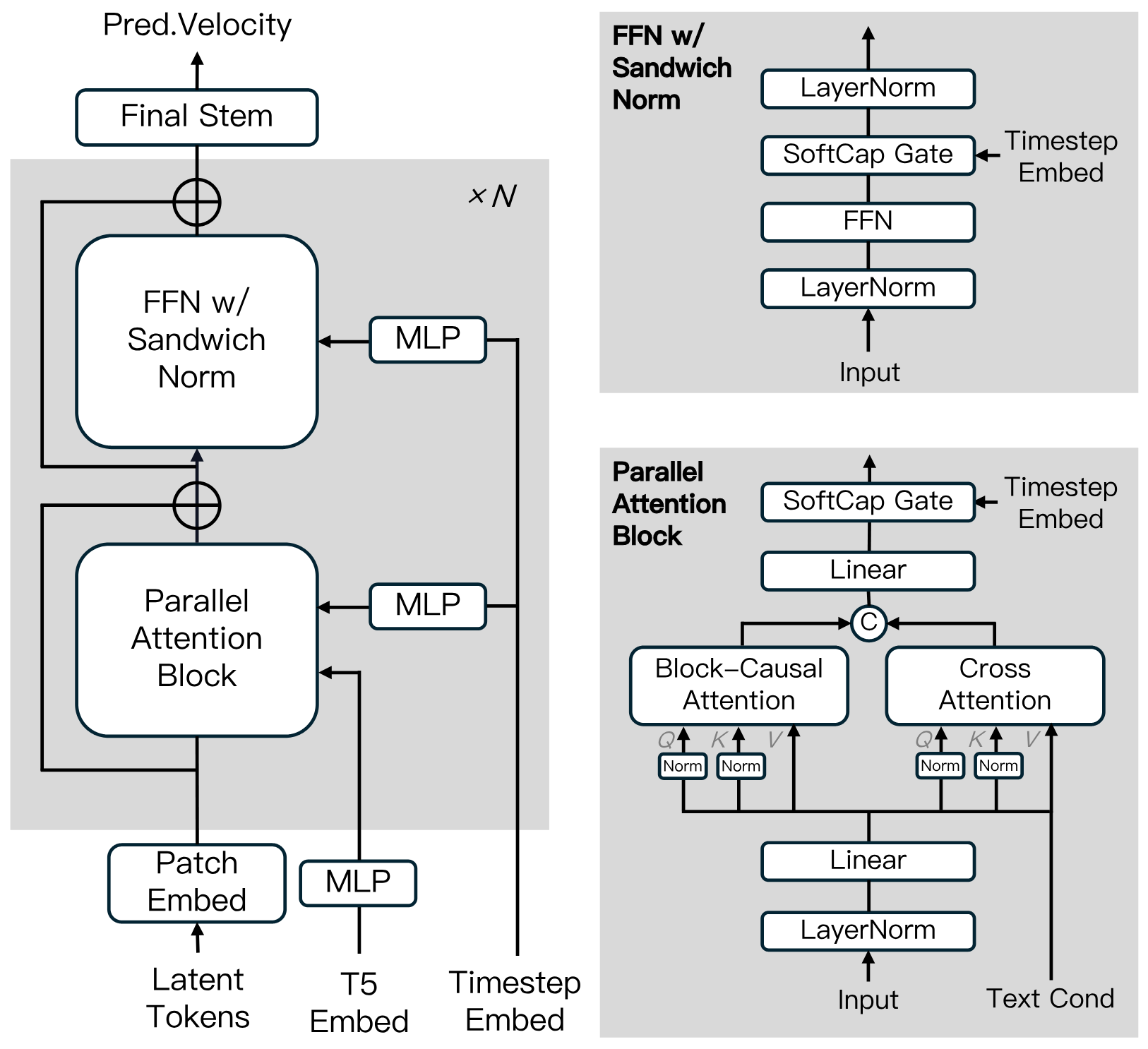
蒸馏算法
使用快捷蒸馏来训练支持可变推理预算的单一速度基础模型。这种方法确保了高效推理,同时将保真度损失降至最低。
MAGI-1:模型库
我们为MAGI-1提供预训练权重,包括24B和4.5B模型,以及相应的蒸馏和蒸馏+量化模型。模型权重链接如表所示。
| 模型 | 链接 | 推荐机器 |
|---|---|---|
| T5 | T5 | - |
| MAGI-1-VAE | MAGI-1-VAE | - |
| MAGI-1-24B | MAGI-1-24B | H100/H800 * 8 |
| MAGI-1-24B-distill | MAGI-1-24B-distill | H100/H800 * 8 |
| MAGI-1-24B-distill+fp8_quant | MAGI-1-24B-distill+fp8_quant | H100/H800 * 4 或 RTX 4090 * 8 |
| MAGI-1-4.5B | MAGI-1-4.5B | RTX 4090 * 1 |
MAGI-1:评估结果
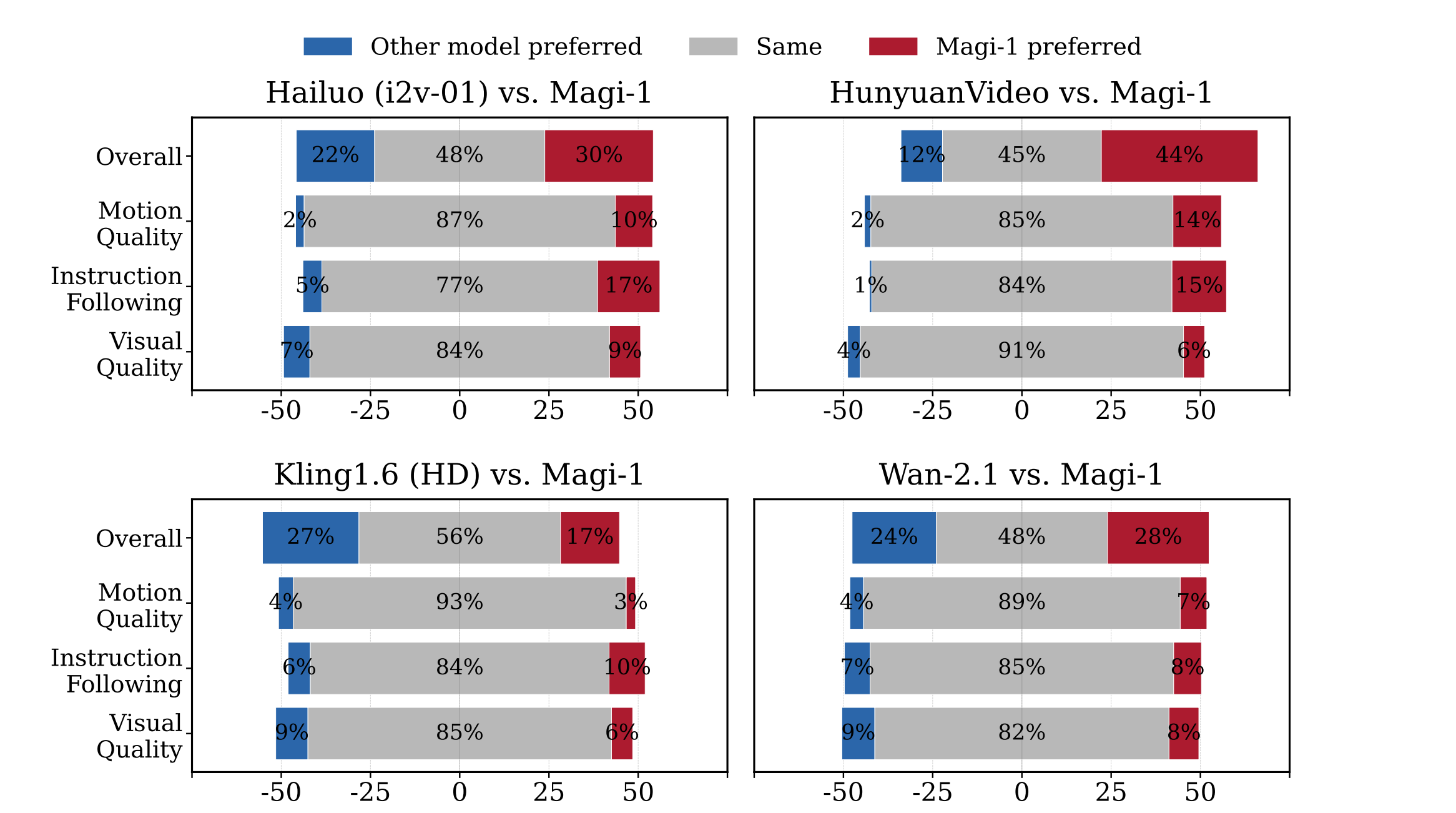
物理评估
MAGI-1展示了 在预测物理行为方面的卓越精确性 ,通过视频延续显著优于现有模型。
| Model | Phys. IQ Score ↑ | Spatial IoU ↑ | Spatio Temporal ↑ | Weighted Spatial IoU ↑ | MSE ↓ |
|---|---|---|---|---|---|
| V2V Models | |||||
| Magi (V2V) | 56.02 | 0.367 | 0.270 | 0.304 | 0.005 |
| VideoPoet (V2V) | 29.50 | 0.204 | 0.164 | 0.137 | 0.010 |
| I2V Models | |||||
| Magi (I2V) | 30.23 | 0.203 | 0.151 | 0.154 | 0.012 |
| Kling1.6 (I2V) | 23.64 | 0.197 | 0.086 | 0.144 | 0.025 |
| VideoPoet (I2V) | 20.30 | 0.141 | 0.126 | 0.087 | 0.012 |
| Gen 3 (I2V) | 22.80 | 0.201 | 0.115 | 0.116 | 0.015 |
| Wan2.1 (I2V) | 20.89 | 0.153 | 0.100 | 0.112 | 0.023 |
| Sora (I2V) | 10.00 | 0.138 | 0.047 | 0.063 | 0.030 |
| GroundTruth | 100.0 | 0.678 | 0.535 | 0.577 | 0.002 |
为什么选择MAGI-1
体验MAGI-1的下一代AI视频创作,在这里尖端技术与开源透明性相遇。
无缝视频生成
通过帧级精确的时间调整掌控您的内容,确保视频完全符合创意规格。
精确时间线控制
生成清晰、细节丰富且动作流畅的视频,确保专业和引人入胜的体验。
增强的运动质量
通过我们先进的运动处理体验逼真的动作,消除机械化过渡,实现真正自然的视频效果。
开源创新
加入一个透明的生态系统,所有模型和研究都可免费获取,促进协作改进和创新。
关于MAGI-1的常见问题
什么是MAGI-1?
MAGI-1 AI是由SandAI开发的先进自回归视频生成模型,通过以自回归方式预测视频片段序列来生成高质量视频。该模型经过训练可以对视频片段进行降噪,实现因果时序建模并支持流式生成。
MAGI-1的主要特点是什么?
MAGI-1 AI视频生成模型的特点包括:基于Transformer的VAE用于快速解码和具有竞争力的重建质量,用于高效视频生成的自回归降噪算法,以及提高大规模训练效率和稳定性的扩散模型架构。它还通过分块提示支持可控生成,实现平滑场景过渡、长期合成和细粒度文本驱动控制。
MAGI-1如何处理视频生成?
MAGI-1 AI采用逐块而非整体方式生成视频。每个块(24帧)都进行整体降噪,当前块达到特定降噪水平后立即开始下一个块的生成。这种流水线设计允许同时处理最多四个块,实现高效的视频生成。
MAGI-1有哪些可用的模型变体?
MAGI-1视频的模型变体包括针对高保真视频生成优化的24B模型和适用于资源受限环境的4.5B模型。还提供经过蒸馏和量化的模型,用于更快的推理。
MAGI-1在评估中表现如何?
MAGI-1 AI在开源模型中达到了最先进的性能,在指令遵循和运动质量方面表现出色,使其成为如Kling1.6等闭源商业模型的强有力潜在竞争对手。它还通过视频延续展示了在预测物理行为方面的卓越精确性,显著优于所有现有模型。
如何运行MAGI-1?
MAGI-1 AI可以使用Docker运行或直接从源代码运行。推荐使用Docker以便于设置。用户可以通过修改提供的run.sh脚本中的参数来控制输入和输出。
MAGI-1的许可证是什么?
MAGI-1在Apache License 2.0下发布。
什么是MAGI-1的'无限视频扩展'功能?
MAGI-1的'无限视频扩展'功能允许无缝扩展视频内容,结合'秒级时间轴控制',使用户能够通过分块提示实现场景过渡和精细编辑,满足电影制作和讲故事的需求。
MAGI-1的自回归架构有什么重要意义?
得益于自回归架构的自然优势,MAGI-1通过视频延续在预测物理行为方面实现了远超现有模型的精确性。
MAGI-1的应用领域有哪些?
MAGI-1设计用于各种应用,如内容创作、游戏开发、电影后期制作和教育。它提供了一个强大的视频生成工具,可用于多种场景。