Meet Your Next AI Friend: The Evolution of AI Human Interaction
From hyper-realistic digital identities to soulful companions—bring your imagination to life with our advanced creation engine.
Create Your Perfect AI Friend
Choose a Category to Start Your Journey By Our AI

AI Anime Friend
Step into the 2D world. Craft your dream anime companion with stunning cel-shaded or manga-style aesthetics.

AI Boyfriend
Design your ideal partner—from the gentle "boy next door" to the charismatic CEO—with personalized personality traits.


AI Girlfriend
Create your perfect companion. Customize every detail of her appearance and emotional intelligence to fit your heart's desire.

AI 3D Friend
Experience the next dimension. Generate hyper-realistic 3D avatars with cinematic lighting and immersive depth.

AI Animal Friend
Who says a friend has to be human? Create magical, talking animal companions or mythical pets with unique spirits.
Unleash Your Creativity: Produce Engaging Video Content
Featuring Your Unique AI Partner
Transform Conversations into Cinematic Stories
Take your relationship to the next level. Don't just text—watch your AI partner speak, move, and react. Our advanced video synthesis engine turns simple prompts into high-definition clips with natural body language and fluid expressions.
Direct Your Own Digital Scenes
You are the director. Whether it's a romantic sunset walk with your AI Girlfriend, a high-octane action sequence featuring your AI 3D Hero, or a cozy vlog with your AI Animal Friend, you control the setting, the motion, and the mood.
Express with Voice & Motion Sync
Bring your videos to life with perfectly synced audio. Upload your voice or choose from our emotional AI voice library to let your partner sing, tell stories, or share heartfelt messages in multiple languages.
Optimized for Social Sharing
Create content that stands out. Easily export your AI interaction videos in formats perfect for TikTok, Instagram, and YouTube. Show the world the unique bond you've built with your digital companion.
Video Showcase
Create Unforgettable Holiday Memories
Don't spend the holidays alone. Whether it's the warmth of a festival or a personal milestone, your AI partner is there to share the joy. Immerse yourself in themed environments that change with the seasons.
Featured Experience: A Magical Christmas
Festive Makeover
Dress your AI Friend in cozy knitted sweaters, reindeer antlers, or elegant holiday attire.
Themed Interaction
Watch them unwrap gifts, decorate a virtual tree, or cozy up by a crackling fireplace.
Holiday Greetings
Receive personalized Christmas carols or heartfelt voice messages to start your morning with a smile.




MAGI-1: Autoregressive Video Generation at Scale
High Performance·Lightweight·Fully Open-SourceMoE Architecture for Multimodal Generation & Understanding
What is MAGI-1 AI?
MAGI-1 is an advanced autoregressive video generation model developed by SandAI, designed to generate high-quality videos by predicting sequences of video chunks in an autoregressive manner. This model is trained to denoise video chunks, enabling causal temporal modeling and supporting streaming generation. MAGI-1 excels in image-to-video (I2V) tasks, providing high temporal consistency and scalability, thanks to several algorithmic innovations and a dedicated infrastructure stack.
Overview of MAGI-1
| Feature | Description |
|---|---|
| AI Tool | MAGI-1 |
| Category | Autoregressive Video Generation Model |
| Function | Video Generation |
| Generation Speed | High-efficiency Video Generation |
| Research Paper | Research Paper |
| Official Website | GitHub - SandAI-org/MAGI-1 |
MAGI-1 AI: Model Features
Transformer-based VAE
Utilizes a variational autoencoder with a transformer-based architecture, offering 8x spatial and 4x temporal compression. This results in fast decoding times and competitive reconstruction quality.
Auto-Regressive Denoising Algorithm
Generates videos chunk-by-chunk, allowing for concurrent processing of up to four chunks for efficient video generation. Each chunk (24 frames) is denoised holistically, and the next chunk begins as soon as the current one reaches a certain level of denoising.

Diffusion Model Architecture
Built on the Diffusion Transformer, incorporating innovations like Block-Causal Attention, Parallel Attention Block, QK-Norm and GQA. Features Sandwich Normalization in FFN, SwiGLU, and Softcap Modulation to enhance training efficiency and stability at scale.
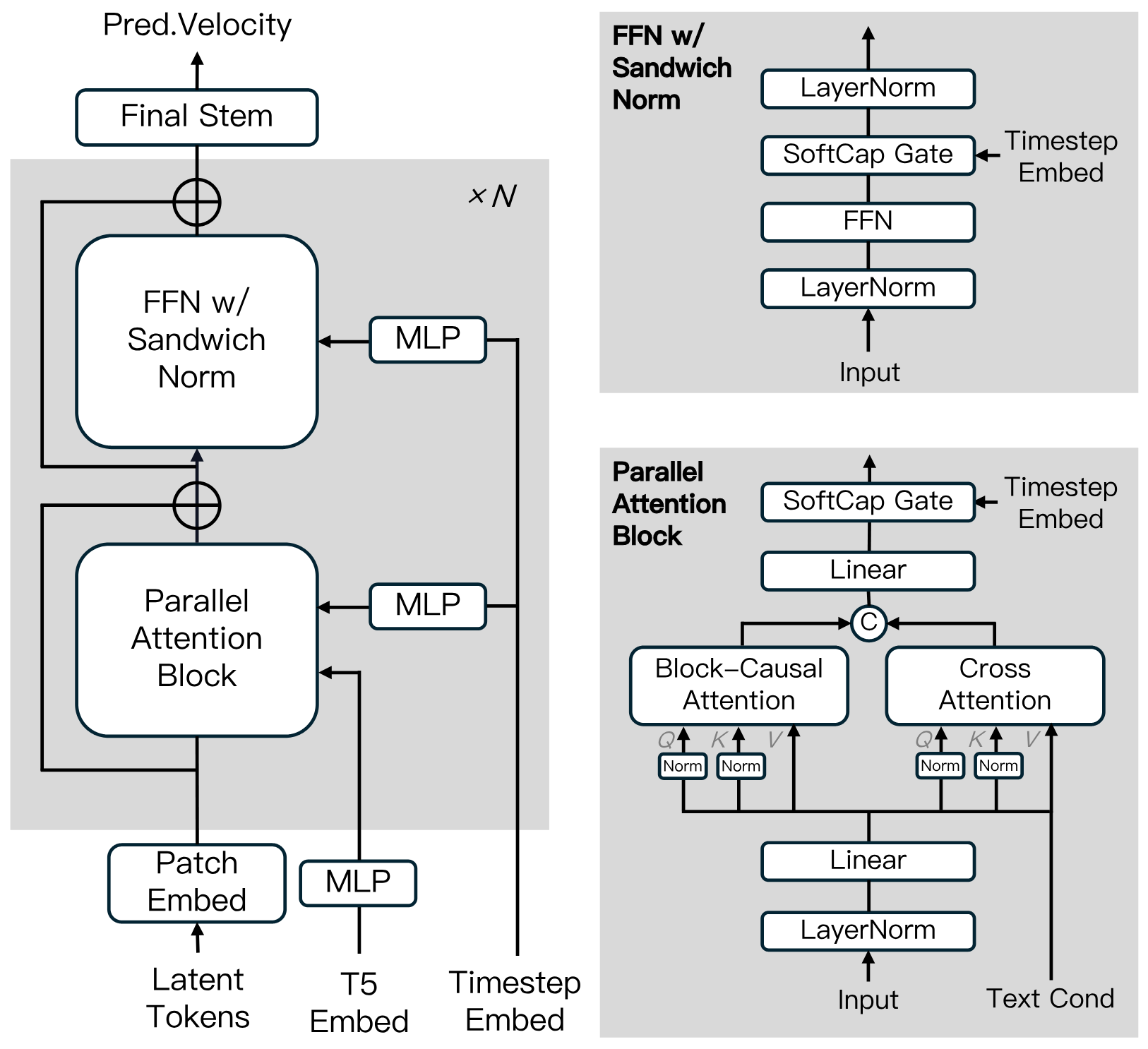
Distillation Algorithm
Uses shortcut distillation to train a single velocity-based model supporting variable inference budgets. This approach ensures efficient inference with minimal loss in fidelity.
MAGI-1: Model Zoo
We provide the pre-trained weights for MAGI-1, including the 24B and 4.5B models, as well as the corresponding distill and distill+quant models. The model weight links are shown in the table.
| Model | Link | Recommend Machine |
|---|---|---|
| T5 | T5 | - |
| MAGI-1-VAE | MAGI-1-VAE | - |
| MAGI-1-24B | MAGI-1-24B | H100/H800 * 8 |
| MAGI-1-24B-distill | MAGI-1-24B-distill | H100/H800 * 8 |
| MAGI-1-24B-distill+fp8_quant | MAGI-1-24B-distill+fp8_quant | H100/H800 * 4 or RTX 4090 * 8 |
| MAGI-1-4.5B | MAGI-1-4.5B | RTX 4090 * 1 |
MAGI-1: Evaluation Results
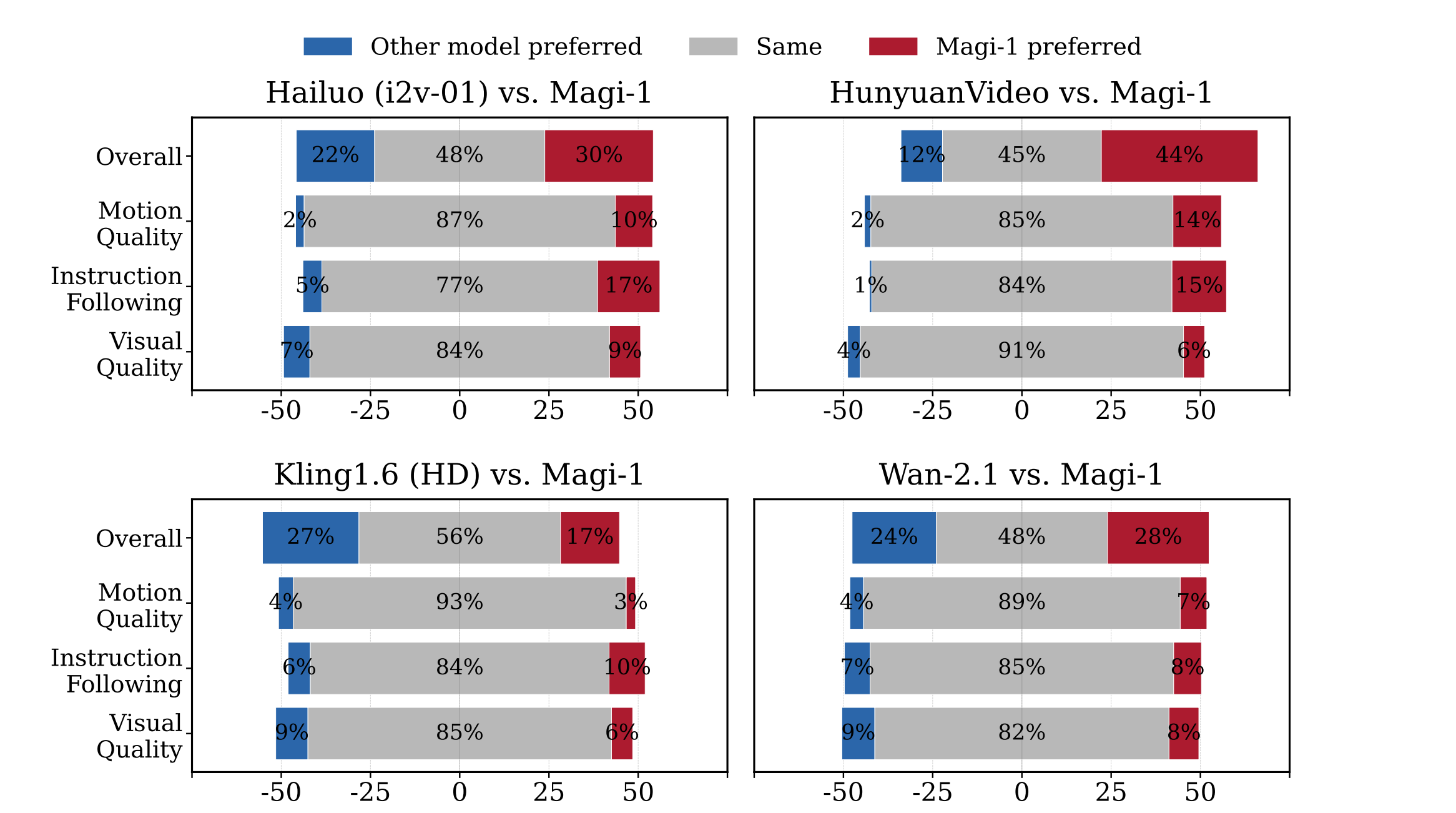
Human Evaluation
MAGI-1 outperforms other open-source models like Wan-2.1, , Hailuo, and HunyuanVideo in terms of instruction following and motion quality, making it a strong competitor to closed-source commercial models.
Physical Evaluation
MAGI-1 demonstrates superior precision in predicting physical behavior through video continuation, significantly outperforming existing models.
| Model | Phys. IQ Score ↑ | Spatial IoU ↑ | Spatio Temporal ↑ | Weighted Spatial IoU ↑ | MSE ↓ |
|---|---|---|---|---|---|
| V2V Models | |||||
| Magi (V2V) | 56.02 | 0.367 | 0.270 | 0.304 | 0.005 |
| VideoPoet (V2V) | 29.50 | 0.204 | 0.164 | 0.137 | 0.010 |
| I2V Models | |||||
| Magi (I2V) | 30.23 | 0.203 | 0.151 | 0.154 | 0.012 |
| Kling1.6 (I2V) | 23.64 | 0.197 | 0.086 | 0.144 | 0.025 |
| VideoPoet (I2V) | 20.30 | 0.141 | 0.126 | 0.087 | 0.012 |
| Gen 3 (I2V) | 22.80 | 0.201 | 0.115 | 0.116 | 0.015 |
| Wan2.1 (I2V) | 20.89 | 0.153 | 0.100 | 0.112 | 0.023 |
| Sora (I2V) | 10.00 | 0.138 | 0.047 | 0.063 | 0.030 |
| GroundTruth | 100.0 | 0.678 | 0.535 | 0.577 | 0.002 |
Why Choose Magi-1
Experience the next generation of AI video creation with Magi-1, where cutting-edge technology meets open-source transparency.
Seamless Video Generation
Take command of your content with frame-accurate timing adjustments, ensuring your videos meet exact creative specifications.
Precise Timeline Control
Produce videos with clear, detailed visuals and smooth motion, ensuring a professional and engaging experience.
Enhanced Motion Quality
Experience lifelike movement with our advanced motion processing, eliminating robotic transitions for truly natural-looking videos.
Open-Source Innovation
Join a transparent ecosystem where all models and research are freely available, fostering collaborative improvement and innovation.
Frequently Asked Questions About MAGI-1
What is MAGI-1?
MAGI-1 AI is an advanced autoregressive video generation model developed by SandAI, designed to generate high-quality videos by predicting sequences of video chunks in an autoregressive manner. This model is trained to denoise video chunks, enabling causal temporal modeling and supporting streaming generation.
What are the key features of MAGI-1?
MAGI-1 AI video generation model features include a Transformer-based VAE for fast decoding and competitive reconstruction quality, an auto-regressive denoising algorithm for efficient video generation, and a diffusion model architecture that enhances training efficiency and stability at scale. It also supports controllable generation via chunk-wise prompting, enabling smooth scene transitions, long-horizon synthesis, and fine-grained text-driven control.
How does MAGI-1 handle video generation?
MAGI-1 AI generates videos chunk-by-chunk instead of as a whole. Each chunk (24 frames) is denoised holistically, and the generation of the next chunk begins as soon as the current one reaches a certain level of denoising. This pipeline design enables concurrent processing of up to four chunks for efficient video generation.
What are the model variants available for MAGI-1?
The model variants for MAGI-1 video include the 24B model optimized for high-fidelity video generation and the 4.5B model suitable for resource-constrained environments. Distilled and quantized models are also available for faster inference.
How does MAGI-1 perform in evaluations?
MAGI-1 AI achieves state-of-the-art performance among open-source models, excelling in instruction following and motion quality, positioning it as a strong potential competitor to closed-source commercial models such as Kling1.6. It also demonstrates superior precision in predicting physical behavior through video continuation, significantly outperforming all existing models.
How can I run MAGI-1?
MAGI-1 AI can be run using Docker or directly from source code. Docker is recommended for ease of setup. Users can control input and output by modifying parameters in the provided run.sh scripts.
What is the license for MAGI-1?
MAGI-1 is released under the Apache License 2.0.
What is the 'Infinite Video Expansion' feature of MAGI-1?
MAGI-1's 'Infinite Video Expansion' function allows seamless extension of video content, combined with 'second-level time axis control,' enabling users to achieve scene transitions and refined editing through chunk-by-chunk prompting, meeting the needs of film production and storytelling.
What is the significance of MAGI-1's autoregressive architecture?
Thanks to the natural advantages of the autoregressive architecture, Magi achieves far superior precision in predicting physical behavior through video continuation—significantly outperforming all existing models.
What are the applications of MAGI-1?
MAGI-1 is designed for various applications such as content creation, game development, film post-production, and education. It offers a powerful tool for video generation that can be used in multiple scenarios.